隨著數字時代的快速發展,全媒體運營師已成為社交媒體行業中不可或缺的關鍵角色。他們不僅需要掌握多樣化的技能,還需在內容創作、用戶互動、數據分析及品牌推廣等多個維度發揮作用。以下是全媒體運營師在社交媒體行業中的主要工作內容:
- 內容策劃與創作:全媒體運營師負責制定社交媒體平臺的內容策略,包括文字、圖片、視頻等多種形式。他們需結合品牌定位和用戶需求,創作吸引人的內容,以提升用戶參與度和品牌曝光率。例如,通過短視頻、直播或圖文推送,傳遞品牌價值并引發用戶共鳴。
- 平臺管理與運營:運營師需熟悉各大社交媒體平臺(如微信、微博、抖音、小紅書等)的規則和特點,進行日常賬號管理。這包括發布內容、回復評論、維護社區氛圍,以及通過活動策劃(如抽獎、話題挑戰)增強用戶粘性。
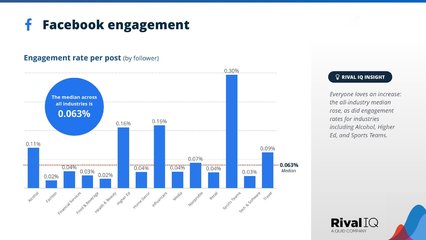
- 數據分析與優化:利用數據分析工具(如Google Analytics、社交媒體后臺數據)監控內容表現,評估用戶行為、流量來源和轉化效果。運營師需基于數據反饋調整策略,優化內容形式和發布時間,以提高傳播效率和投資回報率。
- 用戶互動與社群建設:全媒體運營師需積極與用戶互動,收集反饋并處理投訴,建立品牌忠誠度。通過創建和管理粉絲群、線上社區,促進用戶之間的交流,形成活躍的社群生態,為品牌積累口碑。
- 品牌推廣與營銷合作:運營師常與其他部門或外部合作伙伴協作,策劃整合營銷活動。例如,與KOL(關鍵意見領袖)或網紅合作推廣,參與行業熱點話題,提升品牌在社交媒體上的影響力和市場份額。
- 危機公關處理:在社交媒體環境中,負面信息可能迅速擴散。全媒體運營師需具備危機意識,及時監測輿情,制定應對方案,通過公開透明的方式化解危機,維護品牌形象。
- 技術工具應用與創新:隨著社交媒體技術的不斷更新,運營師需學習使用新興工具(如AI內容生成、AR濾鏡等),以提升運營效率和創意水平。關注行業趨勢,探索新的互動形式和傳播渠道。
全媒體運營師在社交媒體行業中扮演著多面手的角色,從內容到數據,從用戶到品牌,他們的工作貫穿整個數字生態鏈。隨著社交媒體的持續演進,這一職業將繼續拓展邊界,成為推動行業創新的重要力量。